Wine Recommendation System

Development Phase I: Search
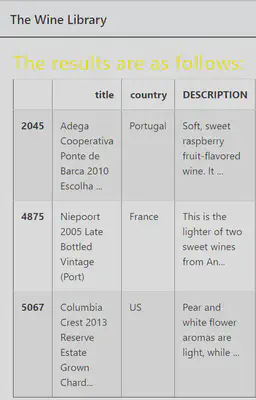
The Wine Recommender System shows top 3 wine list based on user reviews.The Wine Recommender System use Kaggle Wine Taster’s review dataset. To find the top 3 wines, the website uses inverted term frequency for finding similarities between the user query and the wine review.
Background: In the field of information retrival,tf-idf stands for term frequency inverse document frequency.Tf idf gives the measure of how important a word is in the document.Both tf and idf have to be calculate separately.
Procedure:
1)Firstly, we need to load all the necessary libraries and read the dataset which is going to be used.
2)After loading the data, we need to remove stopwords and tokenise each word.
def process_text(text):
text = re.sub('[^a-z\s]', '', text.lower())
text = [w for w in text.split(' ') if w not in set(stopwords)]
return ' '.join(text)
3)Now, we have created our token. We will use tokens to find TF_IDF value. We created two functions for tf and idf which will return tf and idf scores.
tfidf_transformer = TfidfTransformer()
train_tfidf = tfidf_transformer.fit_transform(count_matrix)
4)We will use the following formula for TF_IDF score. Every every t token we will save the TF_IDF value.
5)Now, we will find TF_IDF for user query. We tokenize user uery and find TF_IDF score. We will use below formula to find TF_IDF score.
6)After finding the cosine score,we need to find the cosine similarity score between the terms and the usrer query.
7)We will then rank the the result on the basis of highest cosine similarity score between terms and user query.
Development Phase II: Classification
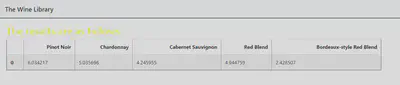
Classification is the process of classifying the user query.In other words, the user would enter the some part of the review of the wine and the system would then classify it in the variety or type of wine it is supposed to be in.Classification will be done on the training data which will train the system.
1)Here for classification we will be using Multinomial Naive Bayes algorithm.It assumes every training data is independent. It also assumes each class is independent from each other.
Here is a step by step algorithm of multinomial naive bayes:
2)Firstly ,we acquire the data i.e.load it.
3)The training data-set contains details and variety of each wine.We will count the number of wines in the whole data-set.
4)Then we will perform stemming and tokenisation on the data i.e.reviews of each wine just like we did in the search feature.
5)Then we will tokenise each data and also put the unique words in the bag of words.
6)Now we will consider user query. The user query also need to tokenized for classification.
Development Phase 3: Recommender System
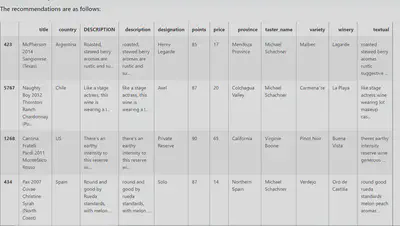
Recommender feature shows top 3 similar wines based on previously selected wines.Wine recommender system uses content-based recommender system. Content-based recommender system gives highest priority to the customer or user preference.To implement this feature, user will first search wines by typing their desire wine description. It will show three wines based on user description. User can get three more similar wines by selecting one wine from the result.To pull off this task, we will be using cosine similarities.
Introduction: In the field of information retrival,tf-idf stands for term frequency inverse document frequency.Tf idf gives the measure of how important a word is in the document.Both tf and idf have to be calculate separately.
Cosine Similarity: After finding TF-IDF for each document and user query, we need to calculate cosine similarity.Cosine similarity is a measure of similarity between two non-zero vectors of an inner product space that measures the cosine of the angle between them. Content-based filtering, also referred to as cognitive filtering, recommends items based on a comparison between the content of the items and a user profile. The content of each item is represented as a set of descriptors or terms, typically the words that occur in a document.
Procedure: The recommender system is very similar to the search feature.
1)After loading data, Wine recommender removes stop words and tokenize each word.
2)Wine recommender calculates TF_IDF score for each token.
3)After setting TF_IDF for training data, Wine Recommender takes user query and perform stemming and lemmatization on the user query. Wine Recommender also tokenizes user query and calculates TF_IDF for each token.
4)After finding all TF_IDF of training data and user query, Wine Recommender calculates cosine similarities between document and user query. Wine Recommender will show the top 3 similar wines based on the user query.
Ashutosh Wagh
Data Scientist
My research interests include distributed robotics, mobile computing and programmable matter.